If you were to ask, “Why did we switch to Model X last quarter?”
A reasoning-based system wouldn’t return a static list of results. It would start in Slack, uncover the early conversations, extract the relevant Jira tickets, analyze the recorded outcomes, and review the supporting documents.
It doesn’t guess. It builds an answer — step by step — from every layer of your workspace.
Search is no longer just about finding information; it’s about understanding it. A new model is emerging, one that behaves less like a tool and more like a teammate.
Reasoning-based search goes beyond retrieval. It breaks down complex questions, creates a plan of action, and moves across systems like Slack, Jira, and Docs to assemble clear, grounded answers.
While modern AI has introduced semantic search — the ability to understand the meaning behind queries — even that remains limited in scope. What’s now taking shape is a multi-step, reasoning-driven approach capable of thinking through ambiguity, adapting to new information, and delivering synthesized insights built on real context.
From Keyword Search to Multi-Step Reasoning
Enterprise search was built for lookup, not logic.
For years, search engines worked by indexing content and matching keywords. A query meant scanning a static index and returning a list of links. Even with semantic upgrades, the process stayed the same: ask once, get back options, and sort through them yourself.
Reasoning-based search introduces a new behavior. Instead of surfacing matches, it starts with a question and charts a path. It breaks down the ask into parts, moves across tools in steps, and builds toward a conclusion. Less like a librarian. More like an analyst.
A Shift in How Search Behaves
This is a fundamental change. Traditional search engines serve static pages of results, while a reasoning-based engine iteratively seeks out the most relevant information. Instead of a single query-response, the AI dynamically plans a multi-step search strategy. It may search one repository, find a clue, then use that clue to query another source, and so on, much like how a human researcher would conduct a thorough investigation. The end result is not just documents but a synthesized answer drawn from multiple sources and reasoning steps.
Powered by LLMs Built for Reasoning
Crucially, this approach leverages the power of advanced large language models (LLMs) to perform active reasoning. New LLMs optimized for reasoning (for example, the DeepSeek-R1 model) demonstrate impressive capability to analyze problems in steps. They can plan and execute a series of searches and deductions, guided by an internal chain of thought.
Such models go beyond retrieving text – they interpret and infer from it. Industry observers note that these reasoning-optimized LLMs make multi-step search feasible in practice, whereas older "static" methods struggled with complex queries.
Privacy-First by Design
A core innovation in reasoning-based search isn't just how it retrieves — it's how it protects. Unlike traditional systems that centralize and duplicate enterprise data, this architecture is designed from the ground up to minimize exposure, honor access boundaries, and reduce long-term storage. The system doesn’t need to store everything to know everything.It doesn’t hoard your data — it uses what’s recent, fetches what’s relevant, and forgets the rest.
Here's how:
Index Recent, Retrieve the Rest
Rather than indexing all enterprise content across all time, the system follows a hybrid strategy: it indexes only recent activity and retrieves older data on demand via secure API access. Most enterprise queries happen within the last several months, so we index and embed that recent data to enable fast, fuzzy, and semantic search. For everything beyond that window, the system doesn't rely on a stored copy. It queries source applications in real time using API-based lookups, scoped entirely to the requesting user.
This design accelerates onboarding, lowers storage requirements, and drastically reduces data exposure. In our architecture, raw documents are not stored long-term. We follow a just-in-time retrieval model that avoids unnecessary exposure. Only indexed and embedded vectors — machine-readable and not reversible — are kept. When raw content is needed to answer a query, it's pulled just-in-time and discarded immediately after.
User-Scoped Crawling
A second pillar of the system's security model is user-scoped crawling. Whether indexing recent content or retrieving historical data via APIs, the system always operates within the requesting user's permission boundaries. It only sees what the user could see manually — no admin access, no elevated visibility, no surprises.
This mirrors the way users already interact with tools like Slack, Drive, Notion, or Jira. The system simply automates that experience, securely and efficiently.
Temporary Cache, Not Permanent Storage
To improve performance during active sessions, a short-lived cache of recently accessed raw content may be held temporarily. This cache is limited in scope and cleared frequently. It exists purely to improve response speed, not for storage.
By avoiding permanent storage of raw data — and limiting even temporary access to the user's own scope — the system reduces the surface area for potential breaches. Only the indexed and embedded vectors persist, and they're not human-readable. The result is a more secure, privacy-aware foundation for enterprise search — designed for speed, built with boundaries, and respectful of the user's view of the world.
Designed for Speed, Privacy, and Trust
This design reduces risk surface, respects access boundaries, and accelerates onboarding without needing to maintain a long-term copy of an organization's full data history.
How the Reasoning-Powered Search Pipeline Works
How does multi-step, reasoning-driven search actually operate under the hood? It involves a pipeline of intelligent steps, orchestrated by both traditional retrieval techniques and modern LLM reasoning. At a high level, the process works as follows:
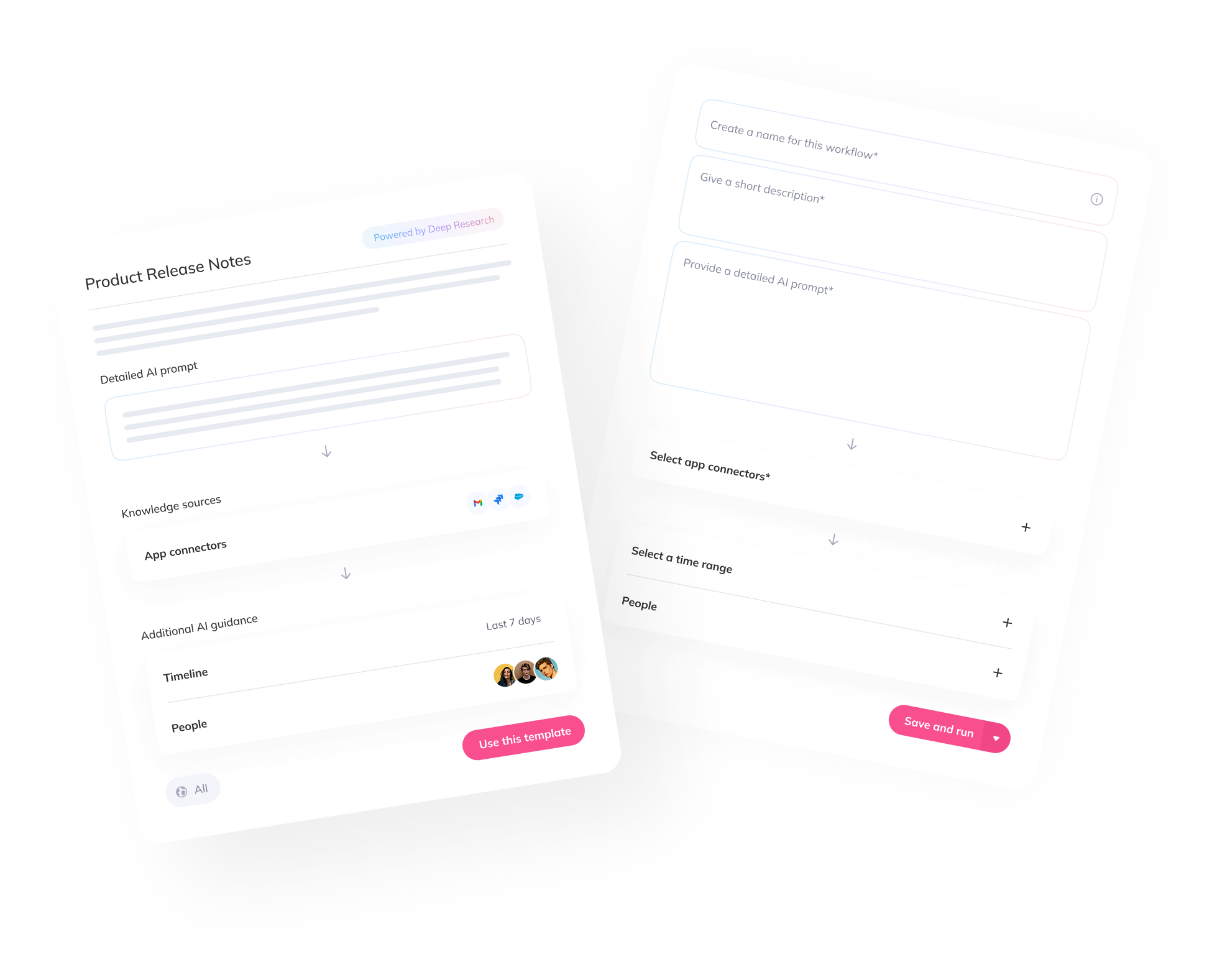
1. Query Planning
When a user submits a query, the reasoning model begins by analyzing the question to understand what's being asked and what kind of steps will be needed to answer it. It doesn't just rephrase the query—it devises a plan.
This might involve identifying key entities, concepts, or references that need further exploration. For example, if the user asks, "Why did we switch to Model X last quarter?", the system may start by searching Slack for early discussions about Model X, extract any referenced Jira tickets or team objections, and then run a follow-up query on Jira to see how the model performed in test environments. From there, depending on what it finds, it may branch into other tools like Notion or Google Drive.
The key distinction is that the system reasons about the query before taking action. It doesn't just search—it thinks about what to search, in what order, and why.
2. Recursive Search Execution
The system follows the plan step by step. After each search, it reads the results and decides what to do next — refine the query, shift to a new app, or dig deeper in the current source. This recursive loop allows the agent to evolve its understanding of the question over time. It doesn't rely on a single pass; it adapts as it learns more from the workspace.
3. Hybrid Retrieval (Index + API)
To search recent content, the system uses indexed and embedded data, typically covering just the past few months. This enables fast semantic and fuzzy keyword search. For historical or long-tail content, it uses secure, real-time API-based lookups directly in the apps (like Slack, Notion, Jira, Google Drive). No raw data is stored permanently, and all retrievals are performed using the user's own permissions.
4. Temporary Working Memory
As results are retrieved, the agent compiles them into a temporary memory — a scratchpad of facts, messages, or relevant excerpts. This memory is ephemeral: it only exists during the session, includes only permission-scoped content, and is not stored or reused across queries. It is not a persistent knowledge graph, but a short-lived context layer to support synthesis.
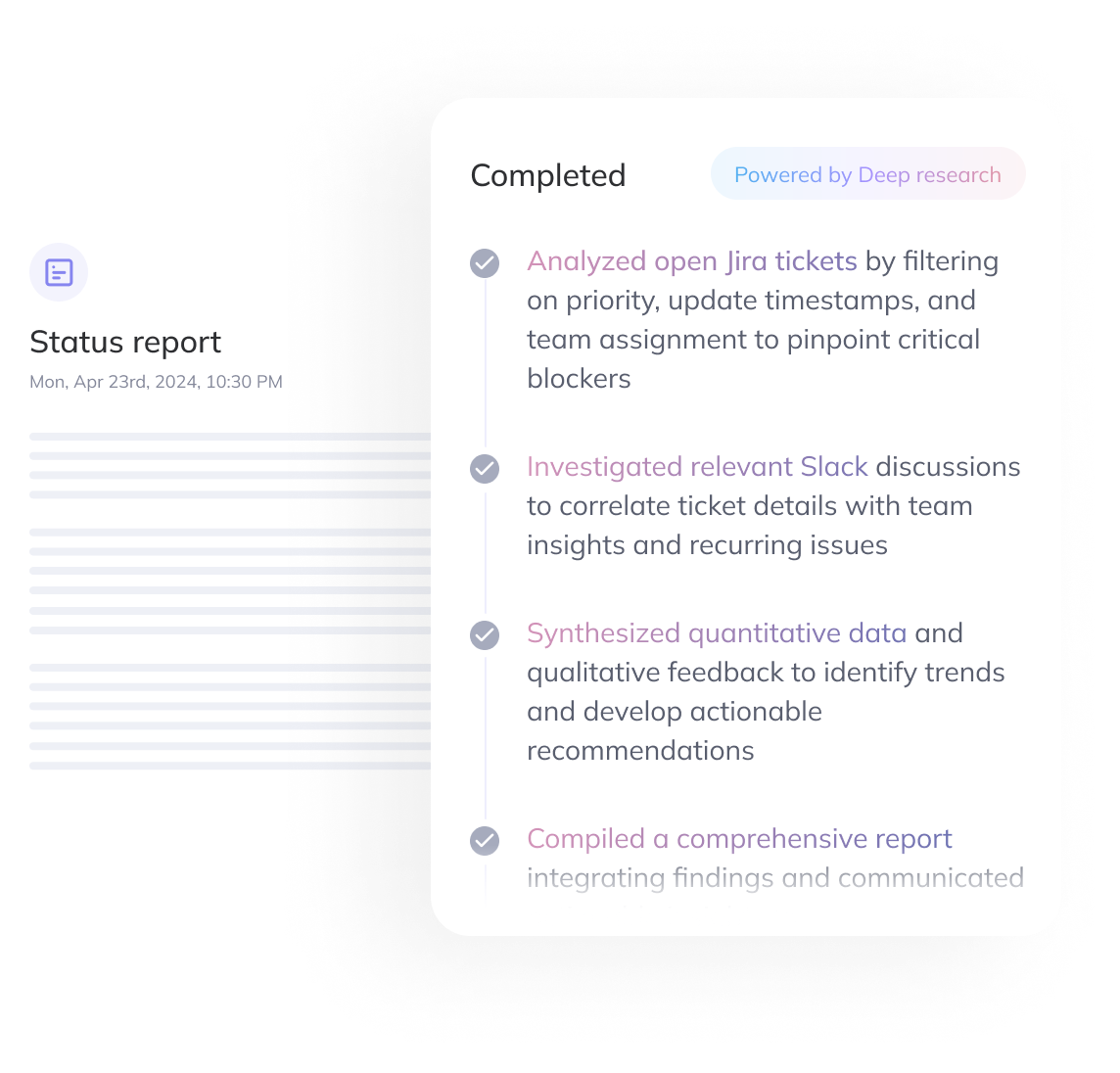
5. Answer Generation
Once the agent has gathered enough information, it generates a synthesized response. This isn't just a string of snippets — it's a grounded, coherent answer that reflects reasoning across steps, often with inline citations. Instead of pushing links or dumps of data, the system delivers a structured summary of what happened — and why — shaped by the user's own workspace.
Throughout this pipeline, the reasoning model plays a conductor role – controlling the flow of the search. It is not just answering questions from a given text; it's actively deciding how to find the answer. This approach has been described as an "agentic" form of RAG, where autonomous AI agents handle the retrieval and reasoning process dynamically. Such an agent uses reflection, planning, and tool use to hone in on the answer iteratively, a stark departure from old search setups that retrieved once and stopped.
Comparing Traditional vs. Reasoning-Based Search
To summarize the differences between legacy enterprise search and this new reasoning-based approach, the following table highlights key aspects:
Aspect | Traditional Enterprise Search | Reasoning-Based Search |
Data Handling | Indexes all content into a central repository. Requires crawling large volumes of raw data and storing human-readable content. | Indexes and embeds only recent data (typically a few months). Older content is accessed via on-demand, permissioned API lookups. No long-term raw data storage. |
Query Processing | Runs a single query against the index. Results are returned in one pass. | Generates a dynamic search plan and executes multiple steps across tools. Each step informs the next. |
Understanding Context | Limited understanding of multi-part or nuanced queries. | Breaks complex questions into sub-tasks, searches iteratively, and refines based on what it finds. |
Results Output | Returns a list of links or document excerpts. User must read and interpret. | Returns a synthesized, grounded answer — often with citations and context pulled from multiple sources. |
Freshness of Data | Relies on index update cycles. May miss recent updates or edits. | Always retrieves live data via APIs. Reflects current state of content at query time. |
Privacy & Security | Central index may contain copies of all company data. Broad access needed for ingestion. | Uses user-scoped retrieval. No raw data duplication. Index is limited to machine-readable vectors and live queries are scoped to the user’s permissions. |
Reasoning Ability | Basic retrieval only. Any analysis must be done manually. | Performs multi-step reasoning: compares, interprets, and draws conclusions across data sources. |
Adaptability | Hard-coded ranking logic. Limited flexibility. | Dynamically adapts its strategy based on search results. More resilient to ambiguity and changing queries. |
As shown above, reasoning-based search solves many of the limitations that older enterprise systems have struggled with, including the complexity of queries, context, and data sensitivity. While some tools are beginning to layer in LLMs for query understanding or summarization, they still largely rely on pre-built indexes and single-pass retrieval.
The real shift happens when search becomes adaptive — when a system can decide what to fetch, how to refine, and when to stop. That means indexing what's needed (and only what's needed), retrieving everything else live, and reasoning through each step like a teammate would. It's not about removing the index — it's about using it surgically, and letting reasoning models do the rest.
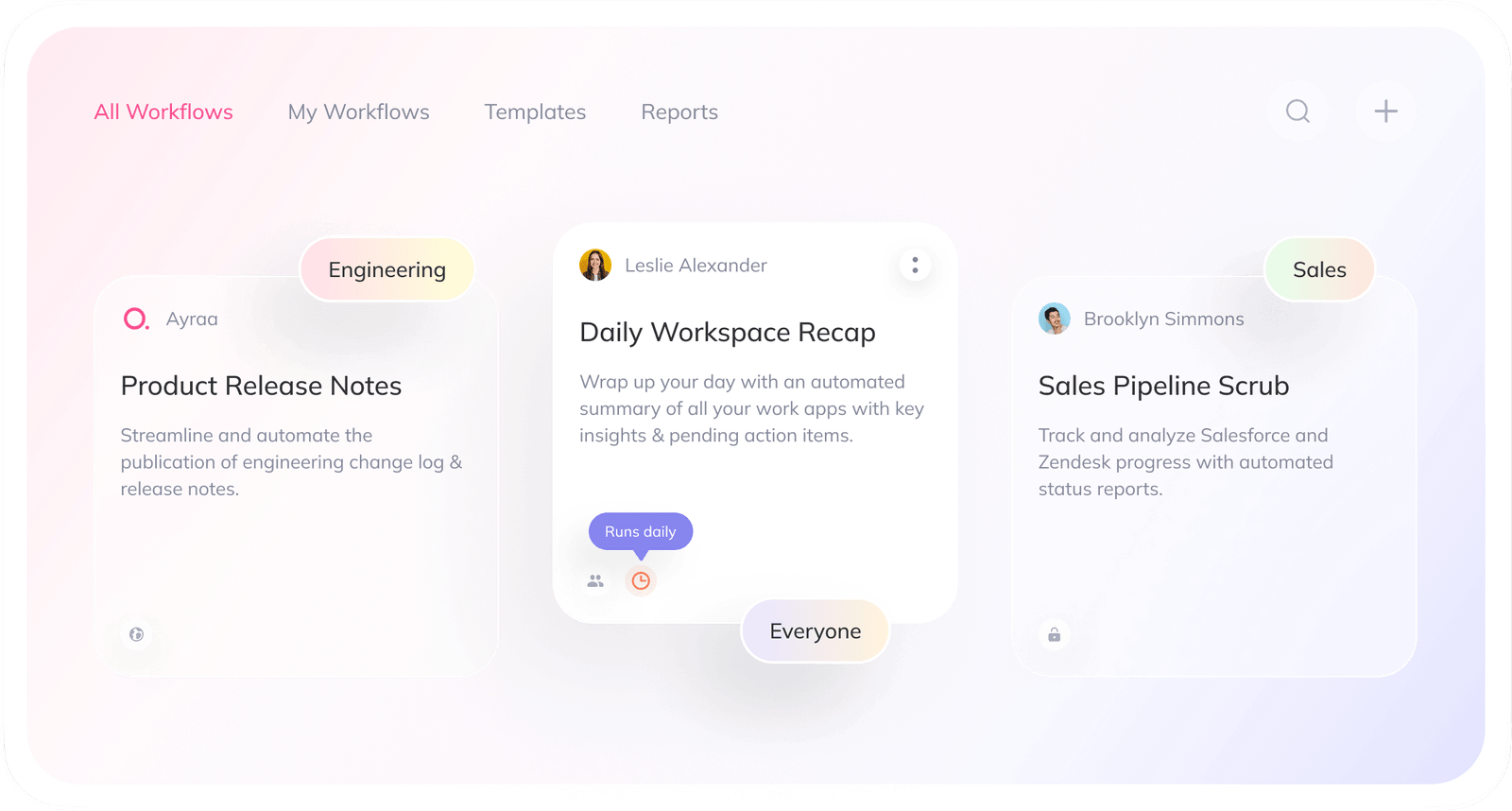
Real-World Use Cases: From Search to Workflow
The true power of reasoning-based search appears when it goes beyond information retrieval and becomes part of your team's workflow. These systems don't just help you find things — they help you finish things. Below are examples rooted in actual needs we've seen across product, engineering, and operations teams:
Reconstructing Past Decisions
A product manager wants to understand why the team chose LLM Model X over Model Y last quarter. The reasoning agent starts by scanning Slack for early conversations around model evaluation. It identifies objections, testing criteria, and references to relevant Jira tickets. Then it searches those Jira tickets for outcomes, timelines, and final approvals. The result? A synthesized report summarizing who said what, when, and why — complete with citations.
Generating Release Notes from Workspace Activity
An engineer is tasked with writing release notes. Instead of manually tracking updates across Jira and Slack, the agent is prompted to look for tickets labeled Q2-release, summarize the key features or fixes, and cross-reference related Slack discussions for implementation context. Once that context is compiled, the agent generates the release note in the correct format — and can even create a draft blog post or social caption from the same material.
Preparing a 9 a.m. Workspace Summary
Imagine starting the day with a summary of everything that changed while you were offline. The agent can compile updates from relevant Jira tickets, Slack threads you were tagged in, key doc edits, and unread emails, organizing them by urgency or topic. No more bouncing between apps to get caught up. Just a clean, contextual brief that shows what matters.
End-of-Week Performance or Incident Reports
Need to recap this week's DevOps incidents? The agent can retrieve logs, ticket updates, and Slack reports related to incidents tagged in the last five business days, then build a timeline of what happened, what was resolved, and what still needs follow-up. It's not just a search—it's an automated report writer.
These aren't just searches. They're workflows. Each of the above scenarios involves multiple systems (Slack, Jira, Docs, Email), and multiple steps of reasoning — from identifying relevant content to synthesizing it for action. What once took an hour of digging now happens in seconds.
Conclusion: The Shift Is Already Here
Search is no longer a query box. It’s a thinking system. One that investigates, reflects, and resolves. The move from keyword matching to reasoning-based search isn't a future trend — it's already reshaping how teams work. This shift transforms how work gets done. Reasoning-based search promises a leap in how organizations harness their knowledge.
And for teams that adopt it, the difference isn’t subtle.
It’s operational intelligence — on demand.